unicode编码表/字符对照表
简单的分类
0000-007F:C0控制符及基本拉丁文 (C0 Control and Basic Latin)
0080-00FF:C1控制符及拉丁文补充-1 (C1 Control and Latin 1 Supplement)
0100-017F:拉丁文扩展-A (Latin Extended-A)
0180-024F:拉丁文扩展-B (Latin Extended-B)
0250-02AF:国际音标扩展 (IPA Extensions)
02B0-02FF:空白修饰字母 (Spacing Modifiers)
0300-036F:结合用读音符号 (Combining Diacritics Marks)
0370-03FF:希腊文及科普特文 (Greek and Coptic)
0400-04FF:西里尔字母 (Cyrillic)
0500-052F:西里尔字母补充 (Cyrillic Supplement)
0530-058F:亚美尼亚语 (Armenian)
0590-05FF:希伯来文 (Hebrew)
0600-06FF:阿拉伯文 (Arabic)
0700-074F:叙利亚文 (Syriac)
0750-077F:阿拉伯文补充 (Arabic Supplement)
0780-07BF:马尔代夫语 (Thaana)
07C0-077F:西非書面語言 (N'Ko)
0800-085F:阿维斯塔语及巴列维语 (Avestan and Pahlavi)
0860-087F:Mandaic
0880-08AF:撒马利亚语 (Samaritan)
0900-097F:天城文书 (Devanagari)
0980-09FF:孟加拉语 (Bengali)
0A00-0A7F:锡克教文 (Gurmukhi)
0A80-0AFF:古吉拉特文 (Gujarati)
0B00-0B7F:奥里亚文 (Oriya)
0B80-0BFF:泰米尔文 (Tamil)
0C00-0C7F:泰卢固文 (Telugu)
0C80-0CFF:卡纳达文 (Kannada)
0D00-0D7F:德拉维族语 (Malayalam)
0D80-0DFF:僧伽罗语 (Sinhala)
0E00-0E7F:泰文 (Thai)
0E80-0EFF:老挝文 (Lao)
0F00-0FFF:藏文 (Tibetan)
1000-109F:缅甸语 (Myanmar)
10A0-10FF:格鲁吉亚语 (Georgian)
1100-11FF:朝鲜文 (Hangul Jamo)
1200-137F:埃塞俄比亚语 (Ethiopic)
1380-139F:埃塞俄比亚语补充 (Ethiopic Supplement)
13A0-13FF:切罗基语 (Cherokee)
1400-167F:统一加拿大土著语音节 (Unified Canadian Aboriginal Syllabics)
1680-169F:欧甘字母 (Ogham)
16A0-16FF:如尼文 (Runic)
1700-171F:塔加拉语 (Tagalog)
1720-173F:Hanunóo
1740-175F:Buhid
1760-177F:Tagbanwa
1780-17FF:高棉语 (Khmer)
1800-18AF:蒙古文 (Mongolian)
18B0-18FF:Cham
1900-194F:Limbu
1950-197F:德宏泰语 (Tai Le)
1980-19DF:新傣仂语 (New Tai Lue)
19E0-19FF:高棉语记号 (Kmer Symbols)
1A00-1A1F:Buginese
1A20-1A5F:Batak
1A80-1AEF:Lanna
1B00-1B7F:巴厘语 (Balinese)
1B80-1BB0:巽他语 (Sundanese)
1BC0-1BFF:Pahawh Hmong
1C00-1C4F:雷布查语(Lepcha)
1C50-1C7F:Ol Chiki
1C80-1CDF:曼尼普尔语 (Meithei/Manipuri)
1D00-1D7F:语音学扩展 (Phonetic Extensions)
1D80-1DBF:语音学扩展补充 (Phonetic Extensions Supplement)
1DC0-1DFF:结合用读音符号补充 (Combining Diacritics Marks Supplement)
1E00-1EFF:拉丁文扩充附加 (Latin Extended Additional)
1F00-1FFF:希腊语扩充 (Greek Extended)
2000-206F:常用标点 (General Punctuation)
2070-209F:上标及下标 (Superscripts and Subscripts)
20A0-20CF:货币符号 (Currency Symbols)
20D0-20FF:组合用记号 (Combining Diacritics Marks for Symbols)
2100-214F:字母式符号 (Letterlike Symbols)
2150-218F:数字形式 (Number Form)
2190-21FF:箭头 (Arrows)
2200-22FF:数学运算符 (Mathematical Operator)
2300-23FF:杂项工业符号 (Miscellaneous Technical)
2400-243F:控制图片 (Control Pictures)
2440-245F:光学识别符 (Optical Character Recognition)
2460-24FF:封闭式字母数字 (Enclosed Alphanumerics)
2500-257F:制表符 (Box Drawing)
2580-259F:方块元素 (Block Element)
25A0-25FF:几何图形 (Geometric Shapes)
2600-26FF:杂项符号 (Miscellaneous Symbols)
2700-27BF:印刷符号 (Dingbats)
27C0-27EF:杂项数学符号-A (Miscellaneous Mathematical Symbols-A)
27F0-27FF:追加箭头-A (Supplemental Arrows-A)
2800-28FF:盲文点字模型 (Braille Patterns)
2900-297F:追加箭头-B (Supplemental Arrows-B)
2980-29FF:杂项数学符号-B (Miscellaneous Mathematical Symbols-B)
2A00-2AFF:追加数学运算符 (Supplemental Mathematical Operator)
2B00-2BFF:杂项符号和箭头 (Miscellaneous Symbols and Arrows)
2C00-2C5F:格拉哥里字母 (Glagolitic)
2C60-2C7F:拉丁文扩展-C (Latin Extended-C)
2C80-2CFF:古埃及语 (Coptic)
2D00-2D2F:格鲁吉亚语补充 (Georgian Supplement)
2D30-2D7F:提非纳文 (Tifinagh)
2D80-2DDF:埃塞俄比亚语扩展 (Ethiopic Extended)
2E00-2E7F:追加标点 (Supplemental Punctuation)
2E80-2EFF:CJK 部首补充 (CJK Radicals Supplement)
2F00-2FDF:康熙字典部首 (Kangxi Radicals)
2FF0-2FFF:表意文字描述符 (Ideographic Description Characters)
3000-303F:CJK 符号和标点 (CJK Symbols and Punctuation)
3040-309F:日文平假名 (Hiragana)
30A0-30FF:日文片假名 (Katakana)
3100-312F:注音字母 (Bopomofo)
3130-318F:朝鲜文兼容字母 (Hangul Compatibility Jamo)
3190-319F:象形字注释标志 (Kanbun)
31A0-31BF:注音字母扩展 (Bopomofo Extended)
31C0-31EF:CJK 笔画 (CJK Strokes)
31F0-31FF:日文片假名语音扩展 (Katakana Phonetic Extensions)
3200-32FF:封闭式 CJK 文字和月份 (Enclosed CJK Letters and Months)
3300-33FF:CJK 兼容 (CJK Compatibility)
3400-4DBF:CJK 统一表意符号扩展 A (CJK Unified Ideographs Extension A)
4DC0-4DFF:易经六十四卦符号 (Yijing Hexagrams Symbols)
4E00-9FBF:CJK 统一表意符号 (CJK Unified Ideographs)
A000-A48F:彝文音节 (Yi Syllables)
A490-A4CF:彝文字根 (Yi Radicals)
A500-A61F:Vai
A660-A6FF:统一加拿大土著语音节补充 (Unified Canadian Aboriginal Syllabics Supplement)
A700-A71F:声调修饰字母 (Modifier Tone Letters)
A720-A7FF:拉丁文扩展-D (Latin Extended-D)
A800-A82F:Syloti Nagri
A840-A87F:八思巴字 (Phags-pa)
A880-A8DF:Saurashtra
A900-A97F:爪哇语 (Javanese)
A980-A9DF:Chakma
AA00-AA3F:Varang Kshiti
AA40-AA6F:Sorang Sompeng
AA80-AADF:Newari
AB00-AB5F:越南傣语 (Vi?t Thái)
AB80-ABA0:Kayah Li
AC00-D7AF:朝鲜文音节 (Hangul Syllables)
D800-DBFF:High-half zone of UTF-16
DC00-DFFF:Low-half zone of UTF-16
E000-F8FF:自行使用區域 (Private Use Zone)
F900-FAFF:CJK 兼容象形文字 (CJK Compatibility Ideographs)
FB00-FB4F:字母表達形式 (Alphabetic Presentation Form)
FB50-FDFF:阿拉伯表達形式A (Arabic Presentation Form-A)
FE00-FE0F:变量选择符 (Variation Selector)
FE10-FE1F:竖排形式 (Vertical Forms)
FE20-FE2F:组合用半符号 (Combining Half Marks)
FE30-FE4F:CJK 兼容形式 (CJK Compatibility Forms)
FE50-FE6F:小型变体形式 (Small Form Variants)
FE70-FEFF:阿拉伯表達形式B (Arabic Presentation Form-B)
FF00-FFEF:半型及全型形式 (Halfwidth and Fullwidth Form)
FFF0-FFFF:特殊 (Specials)
Unicode Table
|
注意:下面这两段是代理区。即第1——16平面的间接表示,四个字节的汉字就在这里表示
D800-DBFF:High-half zone of UTF-16
DC00-DFFF:Low-half zone of UTF-16
iPhone emoji问题牵出的Unicode代理区的思考
在程序员和产品讨论emoji字符占用的字节数的时候,有人说2个、有人说4个、还有开发说iPhone的表情是iOS自定特定的。究竟emoji是几个字符呢?答案是4个,下面详细介绍一下:
在输入框输入一个emoji——微笑,然后通过UTF-8转化工具,看看它的编码是这样:
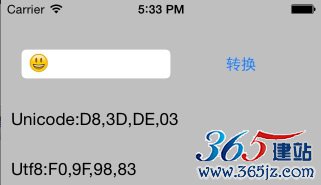
可以看到Unicode编码是 D83D-DE03。utf-8的编码是F09F-9883。常见字符Unicode很少四个字节的,这个不寻常的。通常utf-8是1到3个字节的,也就是说在Unicode编码空间的第0个平面上。可以简单推测:既然emoji的utf-8是4个字节,说明在1,2...16个平面中的某一个 。
这里有必要说明一下utf-8的编码规则 如图所示:
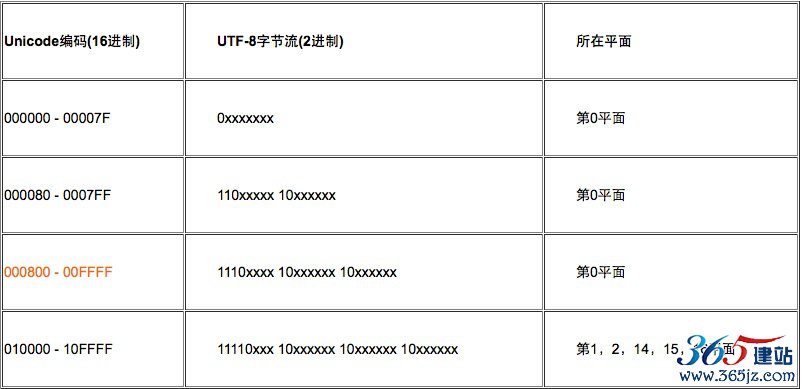
我们再看看“微笑”的emoji符号的Unicode:D83D-DE03,已经超过了表格中最大的0X10FFFF了,怎么回事???下面我们根据utf-8的值:F09F-9883.来反推Unicode对应的数值吧,看看究竟是为什么:

得出的结果是0x1-F603,我把这个值叫做UTF-16.这个结果跟Unicode:D83D-DE03的值相差很大,所以,中间肯定经过了一些转换步骤,这个转换就是utf-16的代理!!!
UFT-16
UTF是"Unicode/UCS Transformation Format"的首字母缩写,即把Unicode字符转换为某种格式之意。上面第二张图片展示的是utf-8和unicode的对应表,这只是一个简单的对应,却非常好用。
在正常情况下一个Unicode两个字节,在转化uft-8的时候,根据协议,两个两个字节,对应一个uft-8这样完成转化或者称为映射!
其实在第0个平面中,专门有一个代理区域,不表示任何字符,只用于指向第1到第16个平面中的字符,这段区域是:D800——DFFF.。其中0xD800——0xDBFF是前导代理(lead surrogates).0xDC00——0xDFFF是后尾代理(trail surrogates).
一个代理对儿(前导,后尾),就表示一个utf-16的字符。就那emoji的微笑来说,前导是代理:D83D;后尾代理是:DE03。根据下图可以得出utf-16的值是:0x1-F603。这就照应上了。
具体的公式是:0x10000 + (前导-0xD800) * 0x400 + (后导-0xDC00) = utf-16编码。
就我们说的例子emoji而言,代入前导和后导,结果是:0x10000+(0xD83D - 0xD800)*0x400 + (0xDE03-0xDC00) = 0x1F603
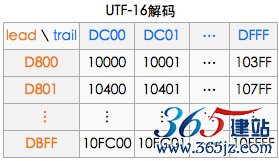
作为程序员的我们,笔者做一个形象的比喻:这对儿(前导代理,后尾代理)就像一个指针,指向了第1——16平面上的每一个码位。经过计算,不难得出:16个平面 * 每个平面码位65536 = 1,048,576个,前导X后尾代理,可以表示的码位也是1,048,576个(哈!真是一个完美的解决方案)如上图所示。
这样做的好处是:程序根据Unicode的第一个字节来判断:(伪代码)
[objc] view plain copy
if(Unicode第一个字节 >=0xD8 && Unicode <=0xDB){
//这是代理区域,表示第1——16平面的字符。每四个字节表示一个单元
}
else{
//这是正常映射区域,表示第0个平面。每两个字节表示一个单元。
}
这样的结果是:根据这个协议判断,计算机可以知道两个字节,还是四个自己表示一个字符。
总结
● emoji 没什么特别的,也是正常的Unicode编码,只是通过代理区实现
● 这里说的utf-8和utf-16,其实本质上是一样的。只是utf-8是一个直接的映射。而utf-16需要根据代理区的(前导代理,后尾代理)来映射。utf-16比utf-8多了一步而已!
● 话又说回来:如果不是代理区域的出现,就emoji 微笑的unicode: 0X1-F603来说。计算机甚至不知道这是一个字符,还是两个字符!所以,搞了一个Unicode:D83D-DE03来表示unicode: 0X1-F603,防止计算机解码混淆!
如对本文有疑问,请提交到交流论坛,广大热心网友会为你解答!! 点击进入论坛

