- 博客(44)
- 收藏
- 关注
 RSS订阅
RSS订阅原创 西瓜书第六章拾遗
西瓜书第六章拾遗间隔与支持向量对偶问题核函数软间隔与正则化支持向量回归核方法间隔与支持向量对偶问题核函数软间隔与正则化支持向量回归核方法
2021-07-29 17:50:56
 218
218
原创 西瓜书第五章拾遗
西瓜书第五章拾遗神经网络的神经元模型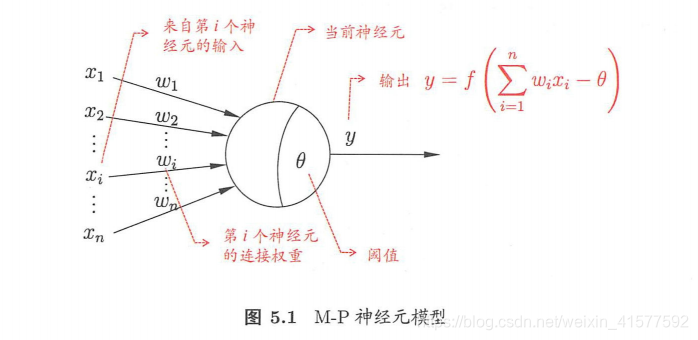感知机与多层网络误差逆
2021-07-25 23:45:29
317
 1
1
原创 西瓜书第四章拾遗
西瓜书第四章拾遗决策树基本流程划分选择信息增益增益率基尼系数剪枝处理预剪枝连续与缺失值连续值处理决策树基本流程划分选择信息增益增益率基尼系数剪枝处理预剪枝预剪枝:是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升, 停止划分并将当前结点标记为叶结点。后剪枝:是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。连续与缺失值连续值处理由
2021-07-22 23:32:17
284
2
原创 西瓜书第三章拾遗
西瓜书第三章拾遗基本形式线性回归对数几率回归线性判别分析( Linear Discriminant Analysis , 简称 LDA)多分类任务类别不平衡问题基本形式线性回归参数估计多元线性回归对数几率回归对数形式:对数似然:线性判别分析( Linear Discriminant Analysis , 简称 LDA)确定w多分类任务多分类任务最经典的拆分策略有 对一”(One vs. One,简称 OvO )、其余”(One vs. Rest ,简称
2021-07-19 17:30:41
82
原创 西瓜书一二章拾遗
西瓜书一二章拾遗版本空间:现实问题中我们常面临很大的假设空间,但学习过程是基于有限样本训练集进行的,因此,可能有多个假设与训练集一致,即存在着一个与训练集一致的“假设集合”,我们称之为“版本空间”(version space )。NFL定理(no free lunch):训练集之外所用样本上的误差与算法的选取无关。NFL前提:所有“问题”出现的机会相同或所有问题同等重要。“平衡点” (Break-Even Po nt ,简称 BEP ):是“查准率=查全率”是的取值。F1度量ROC 全
2021-07-13 22:27:38
94
原创 图神经网络学习总结
总结在话题一,我们学习了基本的图论知识、常规的图预测任务和PyG库的安装与使用;在话题二,我们学习了实现图神经网络的通用范式并实践了图神经网络的构建;在话题三,我们以GCN和GAT(两个最为经典的图神经网络)为例,学习了基于图神经网络的节点表征学习的一般过程,实践了基于PyG的数据全部存于内存的数据集类的构造,并且实践了基于节点表征学习的图节点预测任务和边预测任务;在话题四,我们学习并实践了应对在超大图上进行节点表征学习面临着的挑战的方案;在话题五,我们学习了基于图神经网络的图表征学习的一般过程
2021-07-10 16:22:59
112
原创 超大规模数据集类的创建
超大规模数据集类的创建Dataset基类简介图样本封装成批(BATCHING)与DataLoader类小图的属性增值与拼接实践针对数据集规模超大的应用场景,需要构建一个按需加载样本到内存的数据集类。Dataset基类简介在PyG中,我们通过继承torch_geometric.data.Dataset基类来自定义一个按需加载样本到内存的数据集类。import os.path as ospimport torchfrom torch_geometric.data import Dataset,
2021-07-09 10:48:47
232
原创 基于图神经网络的图表征学习方法
@TOC基于图神经网络的图表征学习方法以图同构网络(Graph Isomorphism Network, GIN)为例学习基于图神经网络的图表征学习。图表征学习要求根据节点属性、边和边的属性(如果有的话)生成一个向量作为图的表征,基于图表征我们可以做图的预测。#基于图同构网络(GIN)的图表征网络的实现计算得到节点表征;对图上各个节点的表征做图池化(Graph Pooling),或称为图读出(Graph Readout),得到图的表征(Graph Representation)。##基于图同
2021-07-05 23:21:14
919
2
原创 超大图上的节点表征学习
超大图上的节点表征学习传统方法的问题Cluster-GCN方法论文提出的方法Cluster-GCN实践传统方法的问题随着图神经网络层数增加,计算成本呈指数增长;保存整个图的信息和每一层每个节点的表征到内存(显存)而消耗巨大内存(显存)空间;无需保存整个图信息和每一层每个节点表征的方法,可能会损失预测精度或者对内存利用率提高不明显。Cluster-GCN方法论文提出的方法利用图节点聚类算法将一个图的节点划分为c个簇,每一次选择几个簇的节点和这些节点对应的边构成一个子图,然后对子图做训练。
2021-07-01 14:20:30
97
原创 数据完整存储与内存的数据集类+节点预测与边预测任务实践
数据完整存储与内存的数据集类+节点预测与边预测任务实践PyG使用数据的一般过程任务实践节点预测任务边预测任务PyG使用数据的一般过程从网络上下载数据原始文件;对数据原始文件做处理,为每一个图样本生成一个**Data对象**;对每一个Data对象执行数据处理,使其转换成新的Data对象;过滤Data对象;保存Data对象到文件;获取Data对象,在每一次获取Data对象时,都先对Data对象做数据变换(于是获取到的是数据变换后的Data对象)。任务实践节点预测任务## 定义GATcl
2021-06-28 00:05:43
183
原创 基于图神经网络的节点表征学习
基于图神经网络的节点表征学习Cora数据集介绍MLP和GCN, GAT节点表征学习能力对比准备工作MLP在图节点分类任务中的应用GCN在图节点分类任务中的应用GAT在图节点分类任务中应用结果对比分析本节中,我们将学习实现多层图神经网络的方法,以及训练图神经网络产生高质量节点表征并实现高准确性节点分类的一般过程。我们的任务是根据节点的属性(可以是类别型、也可以是数值型)、边的信息、边的属性(如果有的话)、已知的节点预测标签,对未知标签的节点做预测。Cora数据集介绍Cora数据集由许多机器学习领
2021-06-23 11:49:50
329
原创 消息传递图神经网络
@[TOC](消息传递图神经网络)消息传递范式最右图为消息传递范式Pytorch Geometric(PyG)中的MessagePassing基类它封装了“消息传递”的运行流程。通过继承MessagePassing基类,可以方便地构造消息传递图神经网络。MessagePassing子类实例GCNConv的数学定义为xi(k)=∑j∈N(i)∪{i}1deg(i)⋅deg(j)⋅(Θ⋅xj(k−1)),\mathbf{x}_i^{(k)} = \sum_{j \in \mathcal
2021-06-19 14:59:16
402
原创 图神经网络——简单图论与环境配置与PyG库
@TOC#图结构数据##图的表示定义一(图):一个图被记为G={V,E}\mathcal{G}=\{\mathcal{V}, \mathcal{E}\}G={V,E},其中 V={v1,…,vN}\mathcal{V}=\left\{v_{1}, \ldots, v_{N}\right\}V={v1,…,vN}是数量为N=∣V∣N=|\mathcal{V}|N=∣V∣ 的结点的集合, E={e1,…,eM}\mathcal{E}=\left\{e_{1}, \ldots, e_{M}\righ
2021-06-16 21:13:49
401
原创 集成学习案例二 (蒸汽量预测)
蒸汽量预测背景介绍数据信息评价指标方法步骤背景介绍火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。数据信息数据分成训练数据(train.txt)和测试数据(test.txt),其中字
2021-05-23 13:42:30
244
原创 集成学习案例一 (幸福感预测)
@TOC幸福感预测#背景介绍比赛的数据使用的是官方的《中国综合社会调查CGSS)》文件中的调查结果中的数据,其共包含有139个维度的特征,包括个体变量(性别、年龄、地域、职业、健康、婚姻与政治面貌等等)、家庭变量(父母、配偶、子女、家庭资本等等)、社会态度(公平、信用、公共服务)等特征。#数据信息赛题要求使用以上 139 维的特征,使用 8000 余组数据进行对于个人幸福感的预测(预测值为1,2,3,4,5,其中1代表幸福感最低,5代表幸福感最高)。#评价指标最终的评价指标为均方误差MSE,即:
2021-05-18 16:06:16
316
原创 集成学习(下)--2
Stacking集成学习算法Stacking集成学习方式Blending与Stacking对比案例Stacking集成学习方式(1) 首先将所有数据集生成测试集和训练集,接下来将训练集分为训练集和验证集进行交叉检验。(2) 交叉检验后可得验证集结果。(3) 将验证集拼接,再将测试集结果加权平均。(4) 运用多个基模型则得到多组结果。合并的验证集作为新的训练集,合并的测试集作为新的测试集,并在此基础上继续进行训练。(5) 再训练基于每个基础模型的预测结果作为特征,在及学习的预测结果上赋权重w可使左
2021-05-13 21:12:57
74
原创 集成学习(下)--1
Blending集成学习算法Blending集成学习方式案例Blending集成学习方式(1) 将数据划分为训练集和测试集(test_set),其中训练集需要再次划分为训练集(train_set)和验证集(val_set);(2) 创建第一层的多个模型,这些模型可以使同质的也可以是异质的;(3) 使用train_set训练步骤2中的多个模型,然后用训练好的模型预测val_set和test_set得到val_predict,test_predict1;(4) 创建第二层的模型,使用val_pred
2021-05-11 21:05:00
57
原创 集成学习(中)--5
XGBoost算法与案例调参XGBoost算法XGBoost的调参说明Xgboost算法案例XGBoost算法XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。数据:D={(xi,yi)}(∣D∣=n,xi∈Rm,yi∈R)\mathcal{D}=\left\{\left(\mathbf{x}_{i}, y_{i}
2021-04-26 17:15:16
88
原创 集成学习(中)--4
@TOC前向分步算法与梯度提升决策树#前向分步算法加法模型在Adaboost模型中,我们把每个基本分类器合成一个复杂分类器的方法是每个基本分类器的加权和。f(x)=∑m=1Mβmb(x;γm)f(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right)f(x)=∑m=1Mβmb(x;γm)其中,b(x;γm)b\left(x ; \gamma_{m}\right)b(x;γm)为即基本分类器,βm\beta_mβm为基本分类器的权重。
2021-04-22 16:34:33
129
原创 集成学习(中)--3
Boosting思路与Adaboost算法Boosting算法Adaboost算法使用sklearn对Adaboost算法进行建模的案例Boosting算法Bagging主要通过降低方差的方式减少预测误差,而Boosting通过不断减少偏差的方式提高最终的预测效果Boosting算法要解决的问题:1.每一轮学习应该如何改变数据的概率分布2.如何将各个弱分类器组合起来Adaboost算法解决问题的方式:提高那些被前一轮分类器错误分类的样本的权重,而降低那些被正确分类的样本的权重。
2021-04-20 17:09:58
60
1
原创 集成学习(中)--2
bagging原理与案例分析bagging的思路bagging原理分析案例bagging的思路Bagging不仅仅集成模型最后的预测结果,同时采用一定策略来影响基模型训练,保证基模型可以服从一定的假设。是通过不同的采样增加模型的差异性。bagging原理分析核心:Bagging的核心在于自助采样(bootstrap)这一概念,即有放回的从数据集中进行采样,也就是说,同样的一个样本可能被多次进行采样。基本流程:首先我们随机取出一个样本放入采样集合中,再把这个样本放回初始数据集,重复K次采样,最终我
2021-04-17 15:43:49
109
原创 集成学习(中)--1
投票法的原理和案例分析投票法的原理分析案例投票法的原理分析投票法:投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。分类1:回归投票法:预测结果是所有模型预测结果的平均值。分类投票法:预测结果是所有模型种出现最多的预测结果。分类2:硬投票:预测结果是所有投票结果最多出现的类。软投票:预测结果是所有投票结果中概率加和最大的类。产生较好结果的条件:基模型之间的效
2021-04-13 22:21:39
124
原创 集成学习(上)--5
分类问题的评估及超参数调优网格搜索和随机网格搜索超参数调优混淆矩阵与ROC曲线网格搜索和随机网格搜索超参数调优网格搜索是一项模型超参数(即需要预先优化设置而非通过训练得到的参数)优化技术,常用于优化三个或者更少数量的超参数,本质是一种穷举法。对于每个超参数,使用者选择一个较小的有限集去探索。然后,这些超参数笛卡尔乘积得到若干组超参数。网格搜索使用每组超参数训练模型,挑选验证集误差最小的超参数作为最好的超参数。[描述来源:MIT press 《Deep Learning》;URL:http://w
2021-03-29 17:58:02
91
原创 集成学习(上)--5
选择具体的模型并进行训练逻辑回归logistic regression:基于概率的分类模型线性判别分析朴素贝叶斯决策树支持向量机非线性支持向量机逻辑回归logistic regression:分类问题与回归问题的区别:在于回归问题与分类问题需要预测的因变量不一样。在回归问题中,因变量是连续性变量;但是在分类问题中,因变量往往是一个离散集合中的某个元素。逻辑回归在实际中不太用于多分类问题,因为实际效果不是很好。基于概率的分类模型线性判别分析基于于贝叶斯公式基于降维分类朴素
2021-03-28 00:30:09
55
原创 集成学习(上)--4
对模型超参数进行调优——调参参数与超参数网格搜索随机搜索参数与超参数岭回归中的参数λ\lambdaλ是一种超参数而参数w是参数。因此,类似于参数w一样,使用最小二乘法或者梯度下降法等最优化算法优化出来的数我们称为参数,类似于一样,我们无法使用最小二乘法或者梯度下降法等最优化算法优化出来的数我们称为超参数。网格搜索sklearn中的GridSearchCV实现了“fit拟合”与“score打分”。如果在估计器中实现了“score_samples得分采样”“predict预测”“predict
2021-03-23 22:03:13
64
原创 集成学习(上)--3
优化基础模型训练均方误差与测试均方误差当我们的模型的训练均方误差达到很小时,测试均方误差反而很大。模型在训练误差很小,但是测试均方误差很大时,我们称这种情况叫模型的过拟合。偏差-方差的权衡:我们的测试均方误差的期望值可以分解为f^(x0)\hat{f}(x_0)f^(x0)的方差、 f^(x0)\hat{f}(x_0)f^(x0)的偏差平方和ε\varepsilonε误差项的方差(建模人物难度/不可约误差)。一般来说,模型的复杂度越高,f的方差就会越大。偏差和方差的关系:
2021-03-22 20:10:16
230
原创 集成学习(上)--2
使用sklearn构建完整的机器学习项目流程使用sklearn构建完整的回归项目完整的机器学习项目流程:明确项目任务:回归/分类收集数据集并选择合适的特征。选择度量模型性能的指标。选择具体的模型并进行训练以优化模型。评估模型的性能并调参。使用sklearn构建完整的回归项目案例一:波士顿房价收集数据集并选择合适的特征:from sklearn import datasetsboston = datasets.load_boston() # 返回一个类似于字典的类X = b
2021-03-18 16:28:11
52
原创 集成学习(上)--1
导论有监督学习:给定某些特征去估计因变量,即因变量存在的时候,我们称这个机器学习任务为有监督学习。无监督学习:给定某些特征但不给定因变量,建模的目的是学习数据本身的结构和关系。根据因变量的是否连续,有监督学习又分为回归和分类:1.回归:因变量是连续型变量2.分类:因变量是离散型变量代码部分:np.unique(): 对于一维数组或者列表,unique函数去除其中重复的元素,并按元素由大到小返回一个新的无元素重复的元组或者列表# 引入相关科学计算包import numpy as npim
2021-03-15 18:35:16
56
原创 CV实践--语义分割6
模型集成集成学习方法深度学习中的集成学习集成学习方法在机器学习中的集成学习可以在一定程度上提高预测精度,常见的集成学习方法有 Stacking、Bagging和 Boosting,同时这些集成学习方法与具体验证集划分联系紧密。那么在 10 个 CNN 模型可以使用如下方式进行集成:对预测的结果的概率值进行平均,然后解码为具体字符;对预测的字符进行投票,得到最终字符。深度学习中的集成学习Dropout在每个训练批次中,通过随机让一部分的节点停止工作。同时在预测的过程中让所有的节点
2021-03-06 19:36:52
191
原创 CV实践--语义分割5
模型训练与验证构造验证集验证集划分法模型训练与验证模型保存与加载构造验证集训练集(Train Set):模型用于训练和调整模型参数;验证集(Validation Set):用来验证模型精度和调整模型超参数;测试集(Test Set):验证模型的泛化能力验证集划分法留出法(hold-out)适用于数据集较大的情况。优点,直接简单;缺点,只得一份验证集,可能导致模型在验证集上过拟合。交叉验证法(cross validation, CV)优点,验证集精度可靠,训练k次得到k个有多样性差异
2021-03-04 17:14:54
119
1
原创 CV实践--语义分割4
评价函数与损失函数TP TN FP FN评价指标Dice 评价指标IOU评价指标BCE 损失函数Focal LossLovász-SoftmaxTP TN FP FNTP(真正例 true positive) TN(真反例 true negative) FP(假正例 false positive) FN(假反例 false negative)Precision=TPTP+FPPrecision = \frac{TP}{TP+FP}Precision=TP+FPTPRecall=TPTP+FN
2021-03-01 21:30:27
336
原创 CV实践--语义分割3
语义分割模型发展FCNFCN原理及结构训练过程SegNetUnetDeepLabRefineNetPSPNet基于全卷积的 GAN 语义分割模型FCNFCN原理及结构FCN 首先将一幅 RGB 图像输入到卷积神经网络后,经过多次卷积以及池化过程得到一系列的特征图,然后利用反卷积层对最后一个卷积层得到的特征图进行上采样,使得上采样后特征图与原图像的大小一样,从而实现对特征图上的每个像素值进行预测的同时保留其在原图像中的空间位置信息,最后对上采样特征图进行逐像素分类,逐个像素计算 softmax 分类损
2021-02-26 17:42:39
637
原创 CV实践--语义分割2
数据扩增数据扩增方法OpenCV和albumentations数据扩增OpenCValbumentationsPytorch 数据读取数据扩增方法用途:增加数据集中样本的数据量,同时也可以有效增加样本的语义空间,防止模型过拟合。注意:不同的数据,拥有不同的数据扩增方法;数据扩增方法需要考虑合理性,不要随意使用;数据扩增方法需要与具体任务相结合,同时要考虑到标签的变化。OpenCV和albumentations数据扩增OpenCV读取图片 cv.imread# 首先读取原始图
2021-02-23 17:31:25
159
原创 CV实践--语义分割
赛题理解与baselinebaseline部分baseline部分引入相关库函数,定义rle编解码函数flatten: 沿纵向(F)平铺(flatten)向量;np.concatenate: 适用于大规模数据拼接,默认axis=0;np.where输出满足条件 (即非0) 元素的坐标;import numpy as npimport pandas as pdimport pathlib, sys, os, random, timeimport numba, cv2, gcfro
2021-02-20 16:16:14
231
原创 Numpy组队学习(下)--大作业(部分)
# 导入数据import numpy as npoutfile = r'D:\test_numpy\iris.csv'iris_csv = np.loadtxt(outfile,dtype = object,delimiter = ',',skiprows = 1)print(iris_csv[0:10])# [['5.1' '3.5' '1.4' '0.2' 'Iris-setosa']# ['4.9' '3' '1.4' '0.2' 'Iris-setosa']# ['4.7' '3.2
2020-12-01 21:31:34
70
原创 Numpy组队学习(下)--4
Numpy组队学习(下)--线性代数矩阵和向量积矩阵特征值与特征向量矩阵分解奇异值分解QR分解Cholesky分解范数和其它数字矩阵的范数方阵的行列式矩阵的秩矩阵的迹解方程和逆矩阵逆矩阵求解线性方程组矩阵和向量积numpy.dot(a, b[, out])// 计算两个矩阵的乘积,如果是一维数组则是它们的内积。矩阵特征值与特征向量numpy.linalg.eig(a) // 计算方阵的特征值和特征向量。numpy.linalg.eigvals(a) // 计算方阵的特征值。矩阵分解奇
2020-11-29 18:45:23
101
原创 Numpy组队学习(下)--3
Numpy组队学习(下)--统计相关次序统计计算最小值计算最大值计算极差计算分位数均值与方差计算中位数计算平均值计算加权平均值计算方差计算标准差相关计算协方差矩阵计算相关系数直方图次序统计计算最小值numpy.amin(a[, axis=None, out=None, keepdims=np._NoValue, initial=np._NoValue, where=np._NoValue])返回数组最小值或沿轴最小值。计算最大值numpy.amax(a[, axis=None, out=Non
2020-11-27 15:23:18
66
原创 Numpy组队学习(下)--2
Numpy组队学习(下)--输入和输出知识点随机抽样离散型随机变量连续型随机变量其它随机函数知识点随机抽样离散型随机变量二项分布binom.pmf(k) = choose(n, k) pk (1-p)(n-k)numpy.random.binomial(n, p, size=None)泊松分布poisson.pmf(k) = exp(-lam) lam*k / k!numpy.random.poisson(lam=1.0, size=None) 超几何分布numpy.ran
2020-11-25 11:24:56
62
原创 Numpy组队学习(下)--1
Numpy组队学习(下)--输入和输出知识点Example知识点numpy文件的保存和读取 numpy.save(file, arr, allow_pickle=True, fix_imports=True) // 保存数组到NumPy文件中( .npy )numpy.load(file, mmap_mode=None, allow_pickle=False, fix_imports=True, encoding='ASCII')// 载入数组或选择的对象(.npy , .npz)或选择的
2020-11-23 14:09:43
62
原创 Numpy组队学习第五次打卡
排序搜索计数及集合操作13 排序,搜索和计数排序13.2 搜索13.3 计数14 集合操作14.1 构造集合布尔运算13 排序,搜索和计数排序返回复制的排序arraynumpy.sort(a[, axis=-1, kind='quicksort', order=None])axis:排序沿数组的(轴)方向,0表示按行,1表示按列,None表示展开来排序,默认为-1,表示沿最后的轴排序。kind:排序的算法,提供了快排’quicksort’、混排’mergesort’、堆排’heapsor
2020-10-31 17:51:53
109
![]()
空空如也
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人