Developed in 2009 at UC Berkeley AMPLab, then
open sourced in 2010, Spark has since become !
one of the largest OSS communities in big data,
with over 200 contributors in 50+ organizations
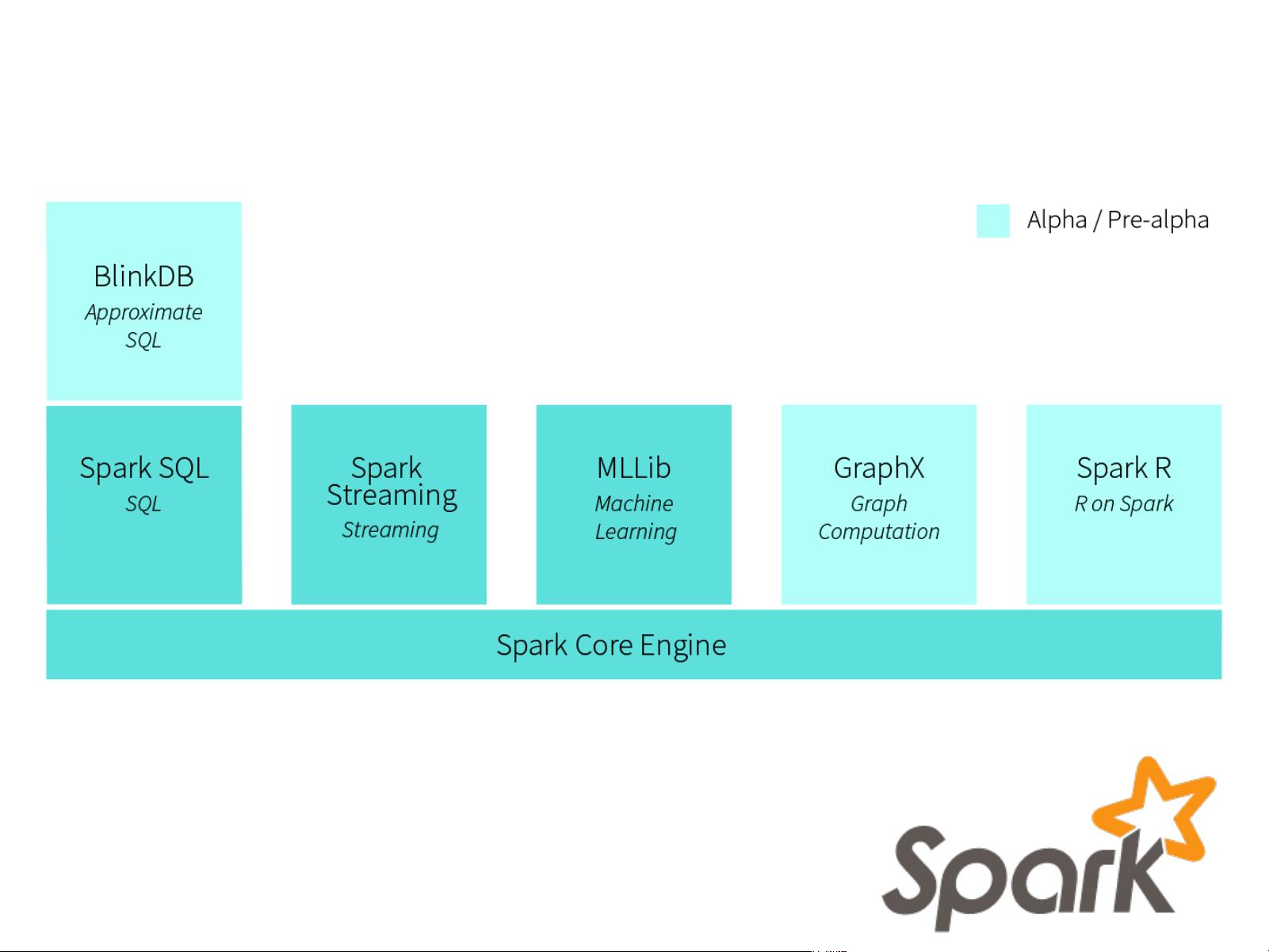
What is Spark?
spark.apache.org
“Organizations that are looking at big data challenges –!
including collection, ETL, storage, exploration and analytics –!
should consider Spark for its in-memory performance and!
the breadth of its model. It supports advanced analytics!
solutions on Hadoop clusters, including the iterative model!
required for machine learning and graph analysis.”!
Gartner, Advanced Analytics and Data Science (2014)
3