

LLM.int8():8
Tim Dettmers*Mike LewisYounes Belkada+ Luke Zettlemoyer
Facebook AIResearch
HuggingFace
ENS
Paris-Saclay
GPU
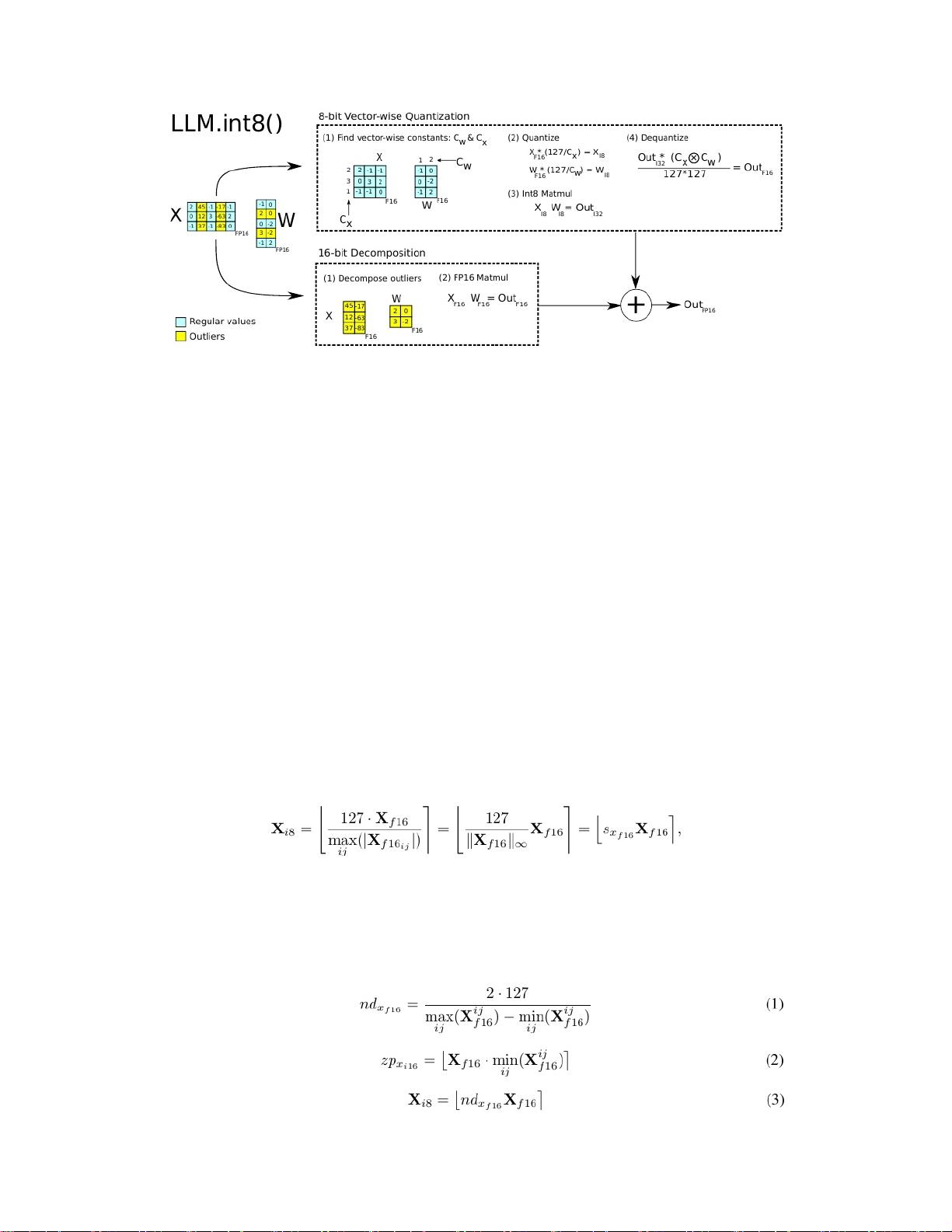
Int8
175B16/32
Int8
transformertransformer
LLM.int8
()
1699.9%
8LLM.int8()llm
175B
gpuOPT-175B/
BLOOM
1
NLP(Vaswani et al. 2017;Radford2019;
2020;Zhang et al. 2022)6.7B
95%
2
65-85% (Ilharco et al. 2020)
transformer8(Chen et al. 2020;Lin et al. 2020;Zafrir
2019;2020)
350M350M
36th Conference on Neural Information Processing Systems (NeurIPS 2022).
*
Majority of research done as a visiting researcher at Facebook AI Research.
2
Other parameters come mostly from the embedding layer. A tiny amount comes from norms and biases.
arXiv: 2208.07339 v2 (csLG] 20221110
https://fanyi.youdao.com/download


剩余19页未读,继续阅读
资源评论














