
HashMap 源码分析源码分析
基于jdk11
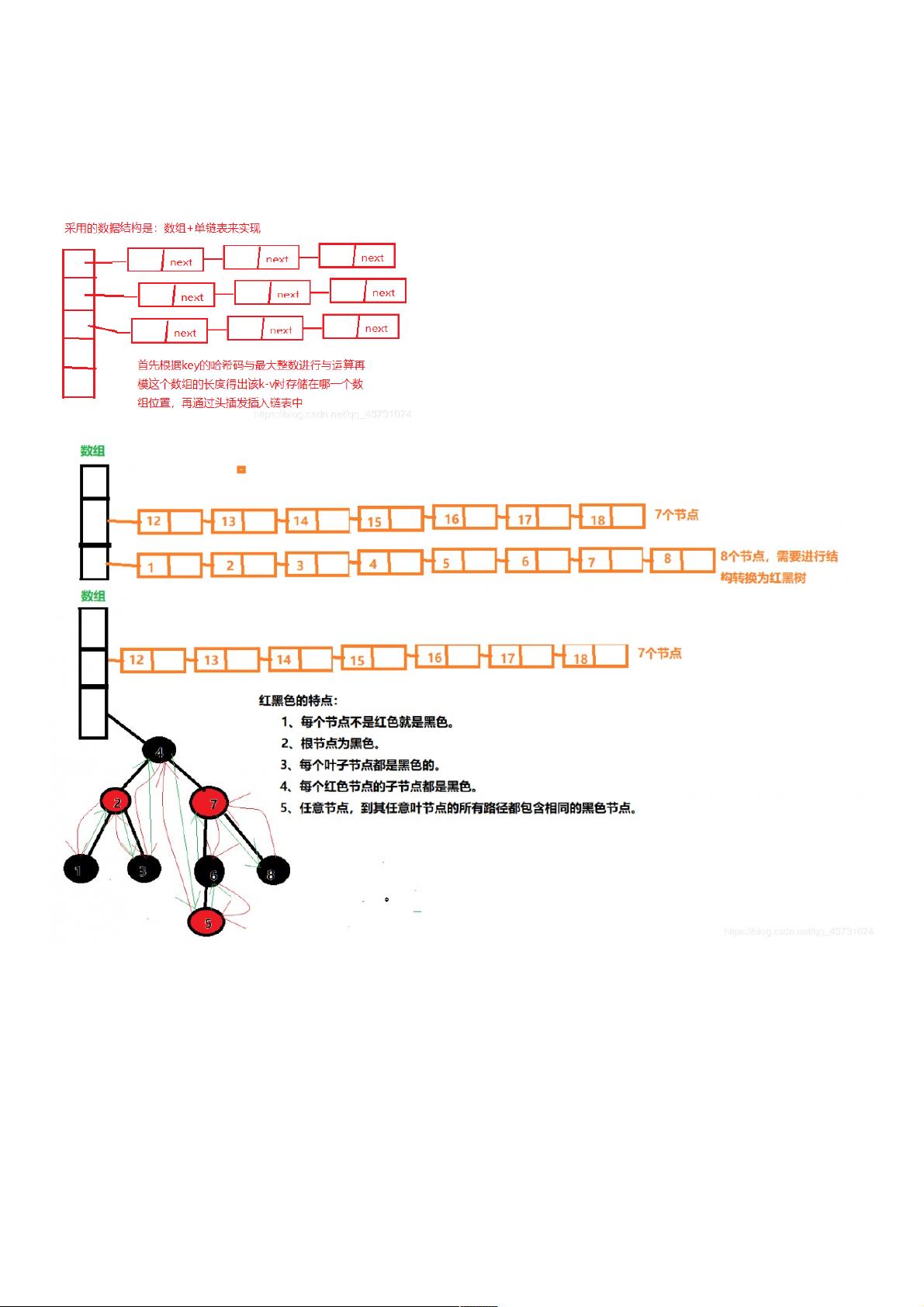
首先,我们了解一下首先,我们了解一下HashMap的底层结构历史,在的底层结构历史,在JDK1.8之前采用的是数组之前采用的是数组+链表的数据结构来存储数据,是不是觉得很熟悉,没错这玩意在链表的数据结构来存储数据,是不是觉得很熟悉,没错这玩意在1.8之前的结构就和之前的结构就和HashTable一样都一样都
是采用数组是采用数组+链表,同样也是通过链地址法链表,同样也是通过链地址法(这里简称拉链法这里简称拉链法)来解决冲突,但是来解决冲突,但是HashMap和和HashTable的区别是一个是线程安全的,一个是非线程安全的。然后知道的区别是一个是线程安全的,一个是非线程安全的。然后知道jdk1.8出来以出来以
后,后,HashMap做性能优化修改,底层数据结构变成了数组做性能优化修改,底层数据结构变成了数组+链表链表+红黑树,性能上也有了很大改变(但还是并发问题,可能这也是为了追求性能而不改的,因为在红黑树,性能上也有了很大改变(但还是并发问题,可能这也是为了追求性能而不改的,因为在JUC包下已经有了包下已经有了
可以支持并发的可以支持并发的HashMap-(ConcurrentHashMap)这个这个Map是支持并发操作的)。是支持并发操作的)。
两种版本的数据结构:
jdk1.8之前:
jdk1.8之后:
了解完上图后是否有疑惑但无所谓,只有看一下HashMap内部的真正数据结构就很容易理解为什么红黑树还有前后继节点
下面是HashMap存储的数据结构:
//这是数组结构,用来存储每个Node及其子类的头接节点的。
transient Node[] table;
//单链表结构
static class Node implements Map.Entry {
//key的哈希码,并非节点Node的哈希码
final int hash;
final K key;
V value;
//后继节点
Node next;
Node(int hash, K key, V value, Node next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
//这是红黑树的树结构
static final class TreeNode extends LinkedHashMap.Entry {
TreeNode parent; // 父母节点
TreeNode left;//左孩子
TreeNode right;//右孩子
TreeNode prev; // 该节点的前继节点,然后你发现Node里面有个后继节点,这样一来这个TreeNode既是红黑树结构也是双链表结构。

剩余8页未读,继续阅读






评论0
最新资源