





































































768
275
Python爬虫批量下载某网站图书以及自动转换成PDF的琐碎记录
2024-07-28 22:15:14
61点赞
368收藏
31评论
前段时间,朋友找我,说发现了一个好网站,上面有很多很不错的电子书,网址是aHR0cHM6Ly9lYm9vay5kc3d4eWp5Lm9yZy5jbi8=
我打开一看,确实挺不错的,正好最近有段时间没写爬虫了,就拿这个网站练练手吧。
看了一下网站,感觉结构挺简单的,应该不会太费劲。
没想到,就此掉进了一个又一个的大坑。
今天,忙里偷闲,记录一下这个过程,免得时间长了就忘记了。
以下都是碎碎念,不喜勿喷。
一、分析网站结构
1.这个网站分了几个大类,每个大类里又细分了多个小类,但不管是大类,还是小类,网址结构都是一样的,都是XXX/ebooks/list/2(主域名用XXX代替了)
2.随便进一个小类,选择其中一本书,可以看到,书籍的网址也是静态的,类似于XXX/ detail/12
3.点击“立即阅读”,会打开新的页面,这里是重点,需要看看这个页面的具体结构。
二、分析阅读页面
经过查看多本书籍的阅读页面,发现一共有2种类型,图片和swf文件。
类型1:展示的页面都是jpg图片,对应的阅读页面特征是:网址结尾是mobile/index.html
对于这个类型,不太好找到总页数,但是观察了一下,一般都是几百页,少数书籍有一千多页,
因此,假设书籍有2000页,写了一个循环,逐个获取图片,
正常情况下,获取图片的requests.status_code应该是200,
如果requests.status_code不等于200,那就说明已经下载完了。
#第一种可能性,是jpg格式
if 'mobile/index.html' in bookurl:
for yema in range(1,2000):
filename1 = str(yema) + '.jpg'
bookurl2 = bookurl.replace('mobile/index.html', 'files/mobile/')+filename1
#不知道有多少页,不好获取。所以,假设有2000页,一个个试
r3 = requests.get(bookurl2, header0)
if r3.status_code==200:
f1 = open(mulu1 + '' + filename1, 'wb')
f1.write(r3.content)
f1.close()
print(filename1)
else:
print(bookname+"___下载完成!")
break
类型2:展示的页面都是swf的动画,对应的阅读页面特征有两种:
一种是flipviewerxpress.html,另一种是类似于“/zbl-2004-1/”
为了方便描述,姑且认为前一种是类型2,后一种是类型3。
目前的浏览器基本上都不再支持swf文件了,经过查询,发现Chrome浏览器的53版本是最后一个支持Flash的版本。
因此,又专门去下载了53版本的Chrome浏览器。
按F12,打开浏览器的开发者模式,观察每一个链接,
能够发现一个特殊的xml格式的链接,这个链接的名字是怎么来的呢?
对于类型2,这个xml的名称类似“cywx2.xml”,其中,cywx2在flipviewerxpress.html里出现过多次,最明显的是网页flipviewerxpress.html的标题,
因此,使用下面的代码,就可以获取到cywx2。
bookurl2 = bookurl.replace('flipviewerxpress.html', '')
r1=requests.get(bookurl,header0)
s1 = BeautifulSoup(r1.text, 'lxml')
title1=s1.title.text#'cywx2'
对于类型3,这个名字直接就是“zbl-2004-1.xml”。
剩下的就是解析这个xml文件,里面有整本书每一页的swf文件地址,如下图所示:
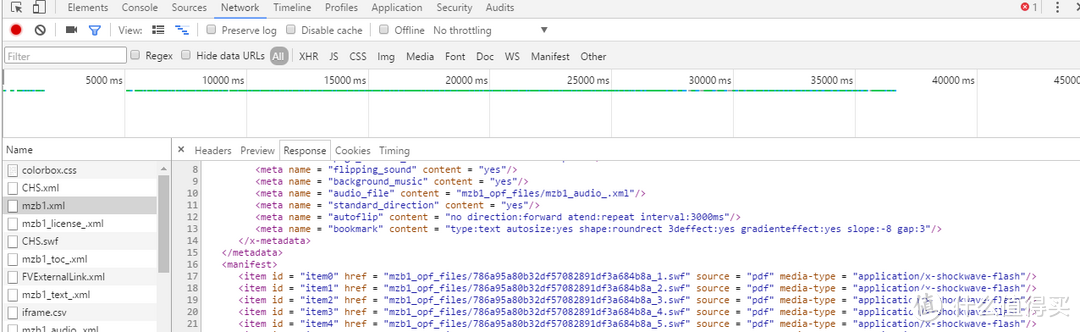
使用正则表达式,把swf地址提取出来,再拼接一下,使用Python下载就行了。
三、Python下载书籍
具体代码就不提供了,只说说思路。
1.先写出下载一本书的代码,
2.再写出解析每一类中书籍列表中的书籍地址,
3.在最上面写一个for循环即可。
但是Python的下载速度比较慢,因此我开了4个Python同时下载。
好在这个网站没有反爬虫措施,可以一直下载。
下载完成以后,一共有17万个swf文件和7万个jpg,总计24万个文件、50多Gb。
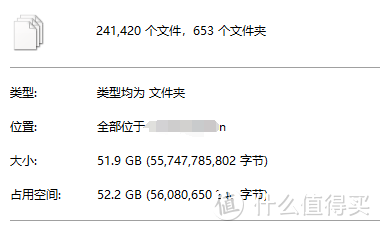
四、将swf文件转为jpg
这也是一个大坑,我在这一步耽误了好几天时间,
后来又经过多次调试,才得到满意的结果。
1.在网上搜索swf转pdf,出来了几个在线网站,但是我测试了一下,都转换不出来,好像是这个swf文件不标准。
其实,即使在线网站能转换,我这也没法用,因为下载后的swf文件有17万多个,我没法一个个上传,在线网站也没法承受这么大的流量。
2.搜索swf转jpg,在52Pojie上发现了一个软件reaConverterPro,试了一下,确实能转换,但是转换后的分辨率太低,文字都看不清楚。
3.后来想到,能否使用Selenium控制浏览器,将swf打印为pdf。
在csdn里搜索到了相关代码,但是我试了几次,都无法正常打印。
通过Selenium控制浏览器,能够正常打开某个swf,也能够使用js代码打开打印窗口,但是会卡在打印界面,未能实现自动确认打印,导致后面的就没法进行了。
4.继续查询,发现Selenium有个截图的功能,那我控制浏览器打开swf文件,再对页面进行截图,岂不是也能解决?
测试了一下,Driver.save_screenshot确实可以截图,但是分辨率不够高,我猜应该是因为显示的页面不够大。
我这个显示器的分辨率是2560*1440,如果把显示器竖起来用,再进行截图,应该可以达到可用的分辨率。
这只是一个初步想法,因为我觉得这个方法太慢了,17万个swf文件,那得需要多长时间去处理。
5.突然想到,在2004年左右,那时候Flash特别火,我也曾经制作过一些Flash,有时候看到别人某个Flash元素比较好,就使用硕思闪客精灵来反编译swf文件,将Flash中的图片、声音等导出来。
找了一下电脑中的文件,竟然还真有这个软件。
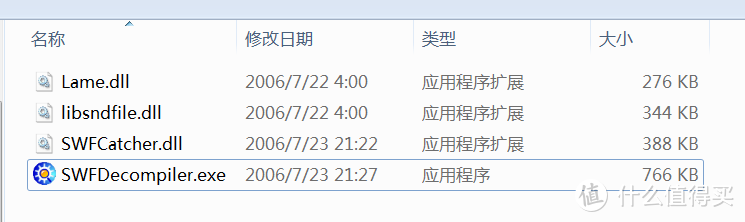
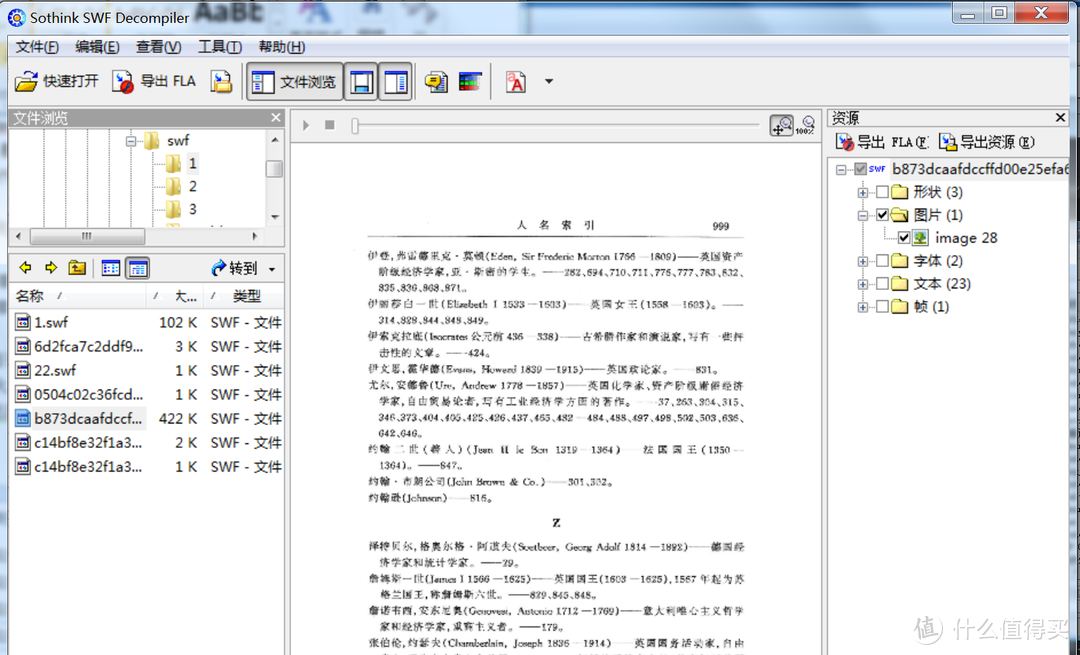
从上图中的右上部分可以看到这个swf文件的结构,也能够导出这些资源,但是问题是只能一个个的导出,17万个swf文件怕不是要疯掉。
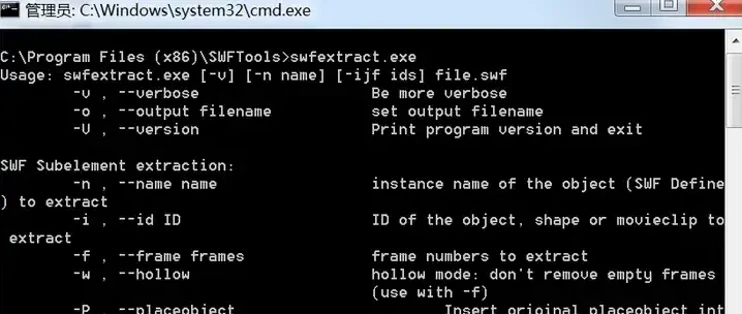
6.继续搜索,有人提到了一个十几年前的软件SwfTools,国内网站上都没有找到下载地址,后来是在GitHub上下载了这个软件。
顺便提一下国内免翻打开GitHub的解决办法,在任意GitHub页面前面加上KK即可,也就是http://kkgithub.com。
安装完SwfTools,在桌面上只有一个绿色的gpdf2swf.exe快捷方式,点开一看,不是我想要的。
根据这个快捷方式,找到SWFToolss的安装目录C:Program Files (x86)SWFTools,发现里面有很多小软件。
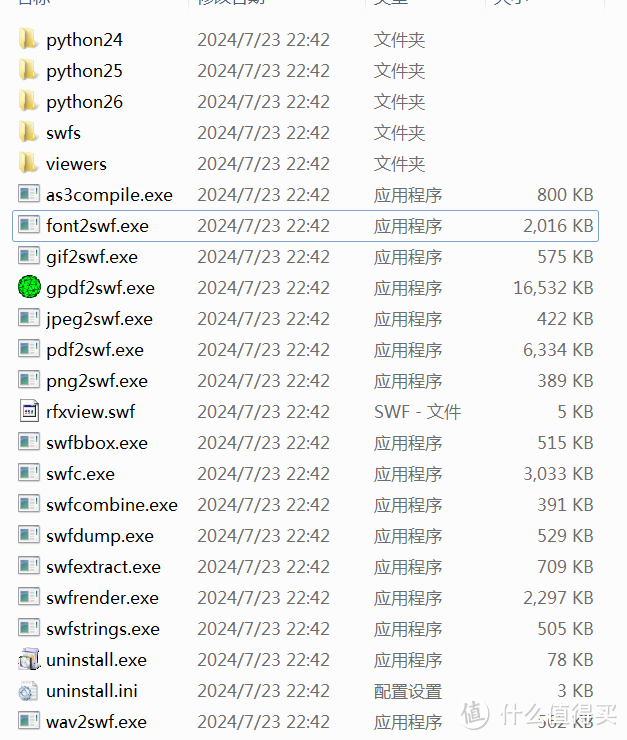
在GitHub页面https://kkgithub.com/swftools/swftools上能看到这些exe程序的功能,
SWFTools
SWFTools is a collection of utilities for working with Adobe Flash files (SWF files). The tool collection includes programs for reading SWF files, combining them, and creating them from other content (like images, sound files, videos or sourcecode). SWFTools is released under the GPL. The current collection is comprised of the programs detailed below:
PDF2SWF A PDF to SWF Converter. Generates one frame per page. Enables you to have fully formatted text, including tables, formulas, graphics etc. inside your Flash Movie. It's based on the xpdf PDF parser from Derek B. Noonburg.
SWFCombine A multi-function tool for inserting SWFs into Wrapper SWFs, contatenating SWFs, stacking SWFs or for basic parameter manipulation (e.g. changing size).
SWFStrings Scans SWFs for text data.
SWFDump Prints out various informations about SWFs, like contained images/fonts/sounds, disassembly of contained code as well as cross-reference and bounding box data.
JPEG2SWF Takes one or more JPEG pictures and generates a SWF slideshow from them. Supports motion estimation compression (h.263) for better compression of video sequences.
PNG2SWF Like JPEG2SWF, only for PNGs.
GIF2SWF Converts GIFs to SWF. Also able to handle animated gifs.
WAV2SWF Converts WAV audio files to SWFs, using the L.A.M.E. MP3 encoder library.
AVI2SWF Converts AVI animation files to SWF. It supports Flash MX H.263 compression. Some examples can be found at examples.html. (Notice: this tool is not included anymore in the latest version, as ffmpeg or mencoder do a better job nowadays)
Font2SWF Converts font files (TTF, Type1) to SWF.
SWFBBox Allows to read out, optimize and readjust SWF bounding boxes.
SWFC A tool for creating SWF files from simple script files. Includes support for both ActionScript 2.0 as well as ActionScript 3.0.
SWFExtract Allows to extract Movieclips, Sounds, Images etc. from SWF files.
AS3Compile A standalone ActionScript 3.0 compiler. Mostly compatible with Flex.
SWFTools has been reported to work on Solaris, Linux (both 32 as well as 64 bit), FreeBSD, OpenBSD, HP-UX, Solaris, MacOS X and Windows 98/ME/2000/XP/Vista.
但是没有写具体用法,那就在cmd里一个个试试看吧。
仔细看了这几个exe的help文件,发现swfrender和swfextract两个程序能够满足要求。
6.1. swfrender.exe
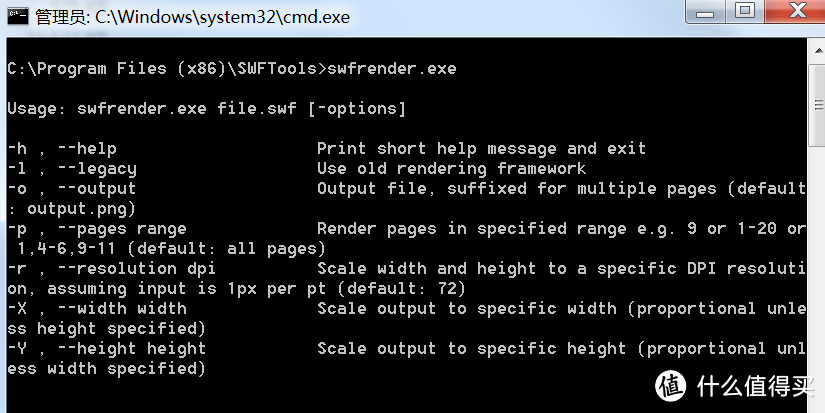
标准用法是:swfrender.exe a.swf -o output.jpg –r 300
这个程序是将swf里的每一帧“打印”出来,输出的时候可以使用-r参数来指定分辨率,默认的分辨率是72,输出的图片基本上看不清楚文字,所以需要提高分辨率。
我使用的是300的分辨率,输出的图片大概是几百KB左右,但是有的彩色照片能达10MB。
swfrender的优点是比较稳定,缺点是比较慢,正常的文字页面基本上是一秒转换一张,图画页面一般是几十秒转换出一张。
而且swfrender占用内存比较大,一般在十几MB,导出时的瞬间可达到大几百MB。
6.2. swfextract.exe
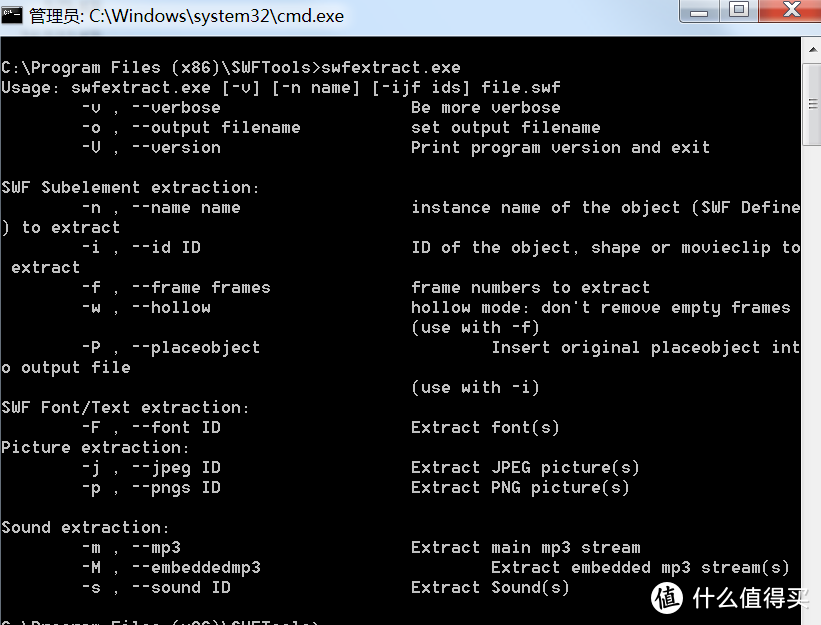
这个程序在使用的时候需要运行2次:
第1次,使用swfextract.exe –v a.swf,查看swf内包含的信息
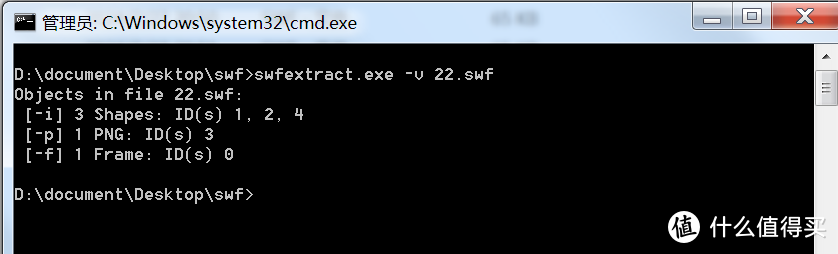
其中Shapes没什么用;从Frame导出来的是另一个swf,也没什么用;唯一有用的就是中间的PNG,id是3。
获取到png的id以后,就可以使用swfextract.exe –o 1.png –p 3 a.swf来导出1.png。导出来的png分辨率还不错,与swf完全一致。
swfextract的优点是导出速度特别快,一秒可以导出200多个swf。缺点是不太稳定。
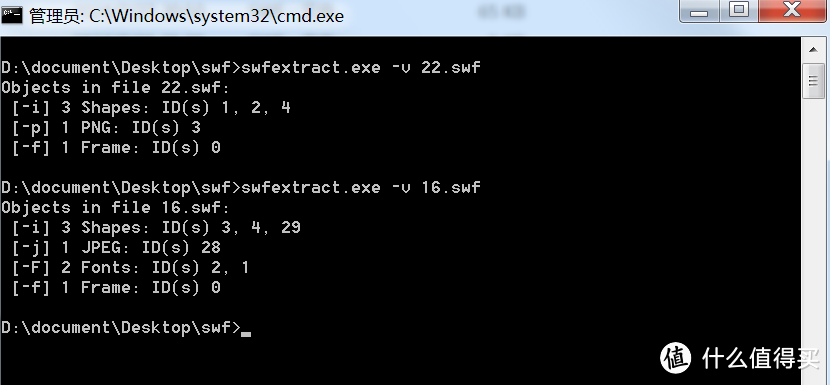
同时要注意,使用swfextract会有几个坑:
一是有的swf里面不是png图片,而是jpg图片,比如:
三是有的swf里面既没有jpg,也没有png,比如:
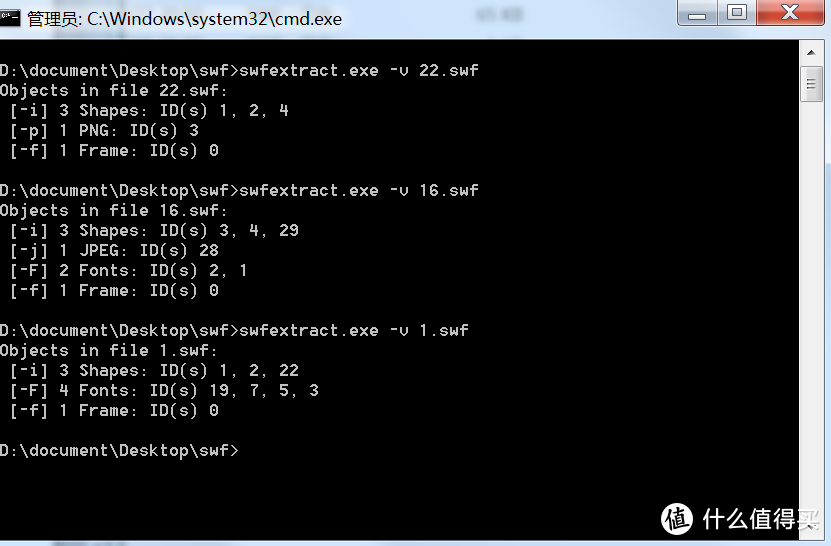
对于以上3种情况,我是这样处理的,
先把swfextract.exe复制3份,分别命名为swfextract1.exe、swfextract2.exe、swfextract3.exe(均衡运行,防止在只有一个swfextract.exe的情况下,运行时跑不急。)
先使用swfextract1.exe –v a.swf,看看这个swf有什么信息,根据输出信息来决定怎么办;
如果里面有JPEG: ID(s),那就使用swfextract2.exe导出为jpg图片;
如果里面有PNG: ID(s),那就使用swfextract3.exe导出为png图片;
如果什么都没有,那就使用swfrender.exe a.swf -o output.jpg –r 300,这个是保底手段。
另外,使用swfextract.exe导出png图片时,经常会遇到swfextract.exe出错的情况,这时整个程序就会暂停,需要手动点击一下,不知道为什么,观察了导出的图片也是正常的。
至此,这十几万个swf文件就可以愉快的转换为图片了。
下面这是把swf转换为图片的Python代码:
import os
import subprocess
folder_path=os.getcwd()
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.endswith('.swf') :
input_file = os.path.join(root, file)
output_file_jpg = input_file[:-4] + ".jpg"
output_file_png = input_file[:-4] + ".png"
if os.path.getsize(input_file)>100:#少于100字节的都是空白页,就不转换了。
if os.path.exists(output_file_jpg) or os.path.exists(output_file_png):
pass
else:
p1 = subprocess.Popen('swfextract1.exe -v '+input_file, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True)
out, err = p1.communicate()
s1=str(out)
#creationflags=subprocess.CREATE_NO_WINDOW的意思是不显示窗口
#把swfextract.exe复制了3份,这样也许能够均衡运行。
if 'JPEG: ID(s)' in s1:
s2=s1.split('JPEG: ID(s)')[1]
JpgId = s2.split('r')[0].strip()
subprocess.run("swfextract2.exe -o " + output_file_jpg + ' -j ' + JpgId + ' ' + input_file,
creationflags=subprocess.CREATE_NO_WINDOW)
elif 'PNG: ID(s)' in s1:
s2 = s1.split('PNG: ID(s)')[1]
JpgId=s2.split('r')[0].strip()
subprocess.run("swfextract3.exe -o "+ output_file_png+' -p '+JpgId+' '+ input_file,creationflags=subprocess.CREATE_NO_WINDOW)
else:
subprocess.run("swfrender.exe " + input_file + ' -o ' + output_file_jpg + ' -r 300',
creationflags=subprocess.CREATE_NO_WINDOW)
print(input_file)
五、将图片转换为pdf文件
转换出这么多图片,一共有90多GB,正常看是没法看的,也不像个书籍的样子。
怎么把这么多图片转换为pdf文件,那就需要请出另一个神器了:abbyy。
在abbyy的15版本里,有一个HotFolder.exe
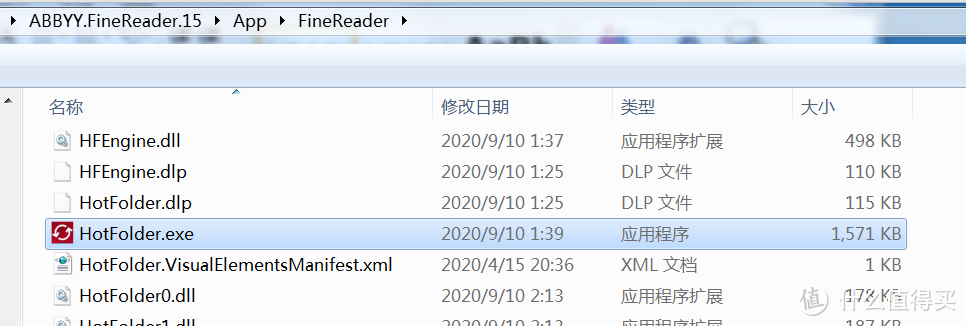
它有以下几个优点:
1.可以将整个文件夹下的图片都自动转换为pdf。
2.可以自动识别子文件夹,而且能够按照文件夹的目录结构生成多个pdf,每个pdf的名字就是当前子文件夹的名字。
3.生成的pdf是双层pdf,也就是已经识别成文字了,可以在pdf里搜索文字。
4.可以定时运行,而且是全自动运行,中间不需要任何干预,让电脑自己跑就行了。
至此,历时两周,终于把所有的文件都下载并转换成pdf文件了。
作者声明本文无利益相关,欢迎值友理性交流,和谐讨论~















卖女孩的火柴棍
二,后面有其他大佬建议,原因在于之前囫囵吞枣,应该得回归基础,找几本书看看。。。
三,目前执行中,但书本看过的内容很快就忘,没啥感觉,对python及其第三库规则or参数还是不甚了解。。。
四,本人非系统开发方向,非程序员,但需要python做统计分析、数据挖掘、规则策略和算法建模,so应该咋办?求指导
校验提示文案
gwmj
校验提示文案
六点半
校验提示文案
值友7979793969
校验提示文案
cutesun
校验提示文案
OO1OO
校验提示文案
虫虫i
校验提示文案
killall911
校验提示文案
麦芽糖的梦
校验提示文案
翻滚的云
校验提示文案
dasautoincq
校验提示文案
Alexzhang2014
校验提示文案
翻云值
校验提示文案
卖女孩的火柴棍
一、数据导入
二、数据预处理(清洗规整、增删改查、数据类型转化)
三、探索分析(可视自动化)
四、特征衍生(组合变量批量自动化生成、特征筛选指标评估自动化)
五、分箱筛选(变量分箱最优自动化)
六、相关性构建(多类算法聚合:逻辑、回归、分类&机器学习、深度学习、强化学习
七、检验评测(第六项计算各自的混淆矩阵指标,自动化计算结果)
八、分数转换
九、超参调优
so针对第二至七项,就python及其第三方库(自动化)实操详解的电子书及其代码而言,特跪求大佬推荐。。。非AI或者chatgpt+XX系列,书籍需求具体如下:
1、小白速成上手、简单易懂
because:文科转型
2、行业内公认靠谱,电子书中文版(暂不考虑:单个某库的说明书)
because:内容忒多繁杂,且无常用算法库的聚合呈现
3、需要2024年出版
because:即使按书实操,旧版书均因为其所涉之第三方库的灭失、相同操作而新旧版本不适配、新旧版本变更操作等原因而导致无法实现同等功能)
校验提示文案
dirstar
校验提示文案
值友5161707429
校验提示文案
值友1777552402
校验提示文案
值友9613429207
校验提示文案
逛张大妈的老法师
校验提示文案
不死心
校验提示文案
逛张大妈的老法师
校验提示文案
cutesun
校验提示文案
值友9613429207
校验提示文案
值友1777552402
校验提示文案
值友5161707429
校验提示文案
dirstar
校验提示文案
卖女孩的火柴棍
二,后面有其他大佬建议,原因在于之前囫囵吞枣,应该得回归基础,找几本书看看。。。
三,目前执行中,但书本看过的内容很快就忘,没啥感觉,对python及其第三库规则or参数还是不甚了解。。。
四,本人非系统开发方向,非程序员,但需要python做统计分析、数据挖掘、规则策略和算法建模,so应该咋办?求指导
校验提示文案
卖女孩的火柴棍
一、数据导入
二、数据预处理(清洗规整、增删改查、数据类型转化)
三、探索分析(可视自动化)
四、特征衍生(组合变量批量自动化生成、特征筛选指标评估自动化)
五、分箱筛选(变量分箱最优自动化)
六、相关性构建(多类算法聚合:逻辑、回归、分类&机器学习、深度学习、强化学习
七、检验评测(第六项计算各自的混淆矩阵指标,自动化计算结果)
八、分数转换
九、超参调优
so针对第二至七项,就python及其第三方库(自动化)实操详解的电子书及其代码而言,特跪求大佬推荐。。。非AI或者chatgpt+XX系列,书籍需求具体如下:
1、小白速成上手、简单易懂
because:文科转型
2、行业内公认靠谱,电子书中文版(暂不考虑:单个某库的说明书)
because:内容忒多繁杂,且无常用算法库的聚合呈现
3、需要2024年出版
because:即使按书实操,旧版书均因为其所涉之第三方库的灭失、相同操作而新旧版本不适配、新旧版本变更操作等原因而导致无法实现同等功能)
校验提示文案
翻云值
校验提示文案
Alexzhang2014
校验提示文案
dasautoincq
校验提示文案
翻滚的云
校验提示文案
值友7979793969
校验提示文案
麦芽糖的梦
校验提示文案
麦芽糖的梦
校验提示文案
killall911
校验提示文案
虫虫i
校验提示文案
六点半
校验提示文案
OO1OO
校验提示文案
gwmj
校验提示文案