













































































467
111
机械革命无界14X(R7-8845HS/Radeon 780M)上运行大模型。
2024-09-14 16:05:20
9点赞
68收藏
26评论
前几天趁着以旧换的补贴搞一台机械革命无界14X,之前买过一台众颜火影U4,7840HS,U4和8845HS一样都是Radeon 780m的GPU,之前就在那台机器上折腾到一半后来没时间,刚好无界14X到手就接着折腾。
AMD现在在AI方面有很多技术,啥子iGPU,APU,NPU眼花缭乱,框架就又是有好几种。
像是这个RyzenAI框架,
https://ryzenai.docs.amd.com
https://github.com/amd/RyzenAI-SW
还有图形框架Vulkan
https://www.vulkan.org/
https://www.amd.com/en/products/graphics/ecosystems/vulkan.html
对于不想折腾的人就直接下载一个LM Studio就可以直接运行,LM Studio采用了Vulkan框架结
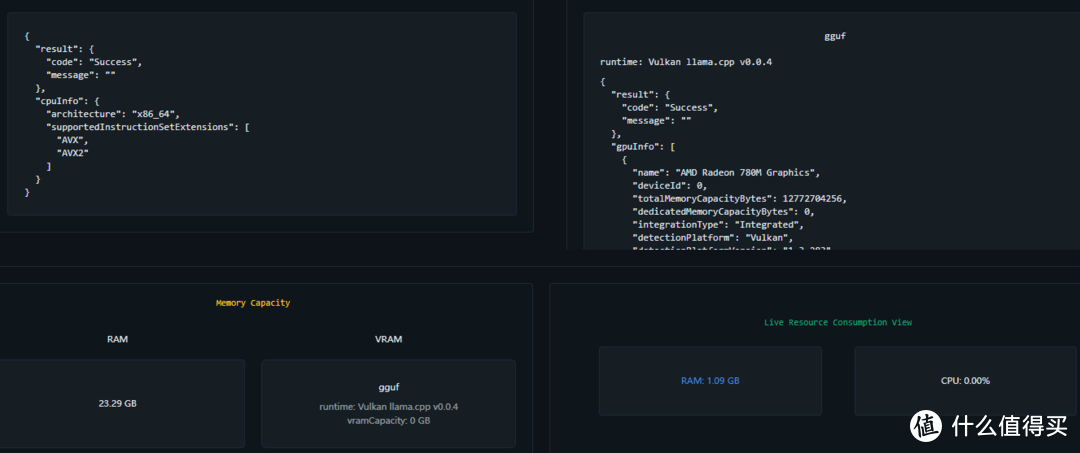
下载好模型记得在模型设置上把GPU带上就可以了
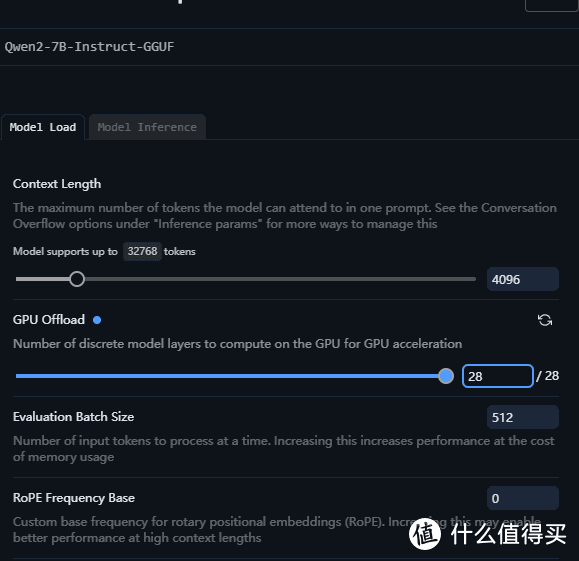
但是不知道为什么速度不是特别理想,在Qwen2 7B模型下只有10+token/s
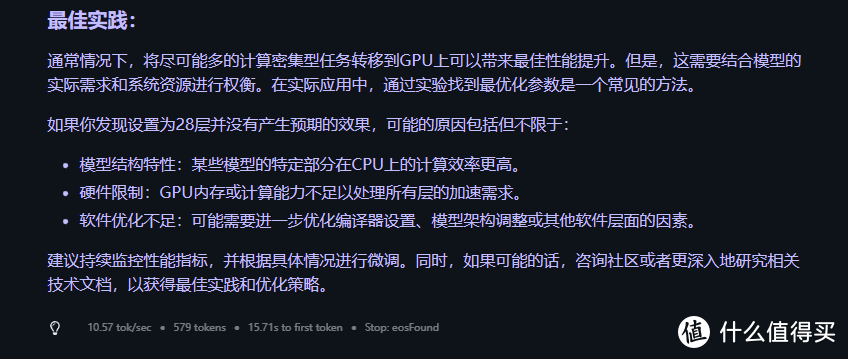
于是想换成Ollama的ROCm方式看看效果会不会好一点。
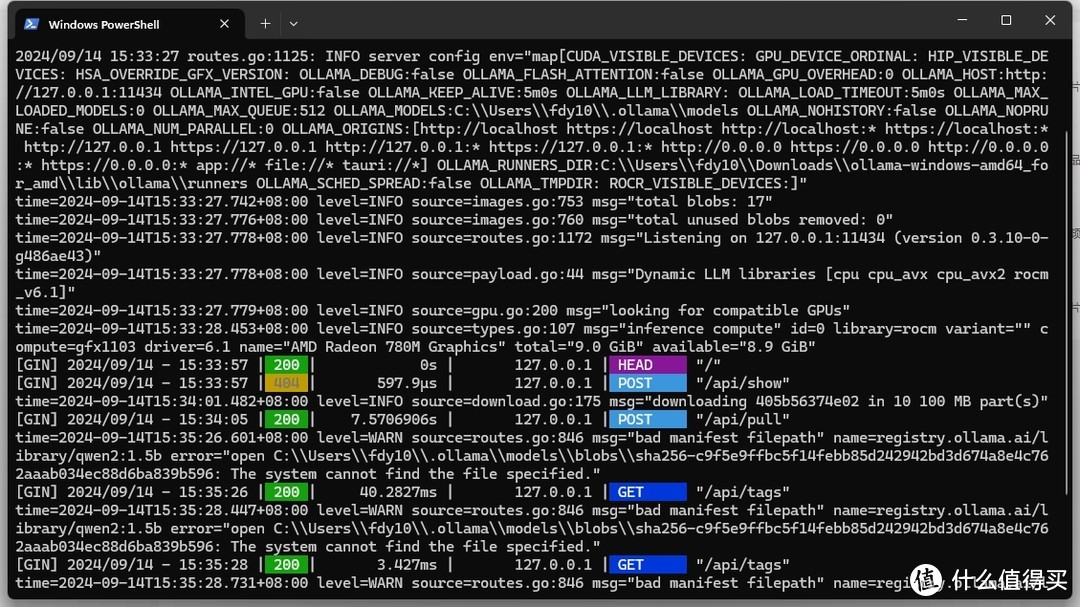
由于Ollama没有支持780mGPU的gfx1103的版本库,所以采用了第三方的https://github.com/likelovewant/ollama-for-amd/
根据Wiki介绍以为直接下载就好了但是加载模型时候会报错,作者没有说明需要安装VC运行环境库。
time=2024-09-13T15:05:04.820+08:00 level=ERROR source=sched.go:456 msg="error loading llama server" error="llama runnerprocess has terminated: exit status 0xc0000005"
这个问题搞了半天,因为是依赖ROCm所以又把HIP安装了不同的版本 (https://www.amd.com/en/developer/resources/rocm-hub/hip-sdk.html)。又认为是驱动不行,又更新驱动,搞半天都不行。
后来单独运行这行命令能够成功,那就明确了不是HIP和驱动的问题。
ollama-windows-amd64_for_amdlibollamarunnersrocm_v6.1ollama_llama_server.exe --model C:Usersxxx.ollamamodelsblobssha256-8de95da68dc485c0889c205384c24642f83ca18d089559c977ffc6a3972a71a8 --ctx-size 8192 --batch-size 512 --embedding --log-disable --n-gpu-layers 25 --parallel 4 --port 55978
最后把整个ollama-windows-amd64_for_amdlibollama目录下的vc环境文件拷贝到ROCm_v6.1的目录下,就可以运行了。之前在众颜火影U4能顺利运行的原因应该是安装过别的软件时顺带安装了VC运行环境。
首先启动ollama服务器 .ollama.exe serve
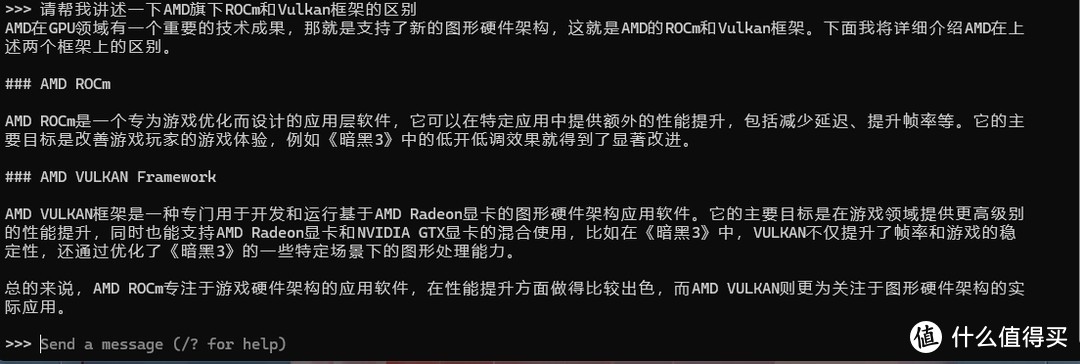
然后再开一个窗口启动加载模型 .ollama.exe run qwen2:7b 等待Send a message提示出来就可以输入Prompt了。
当然也可以采用别代UI的App 比如 https://chatboxai.app/ 简单设置好本地的ollama服务器地址就可以使用了
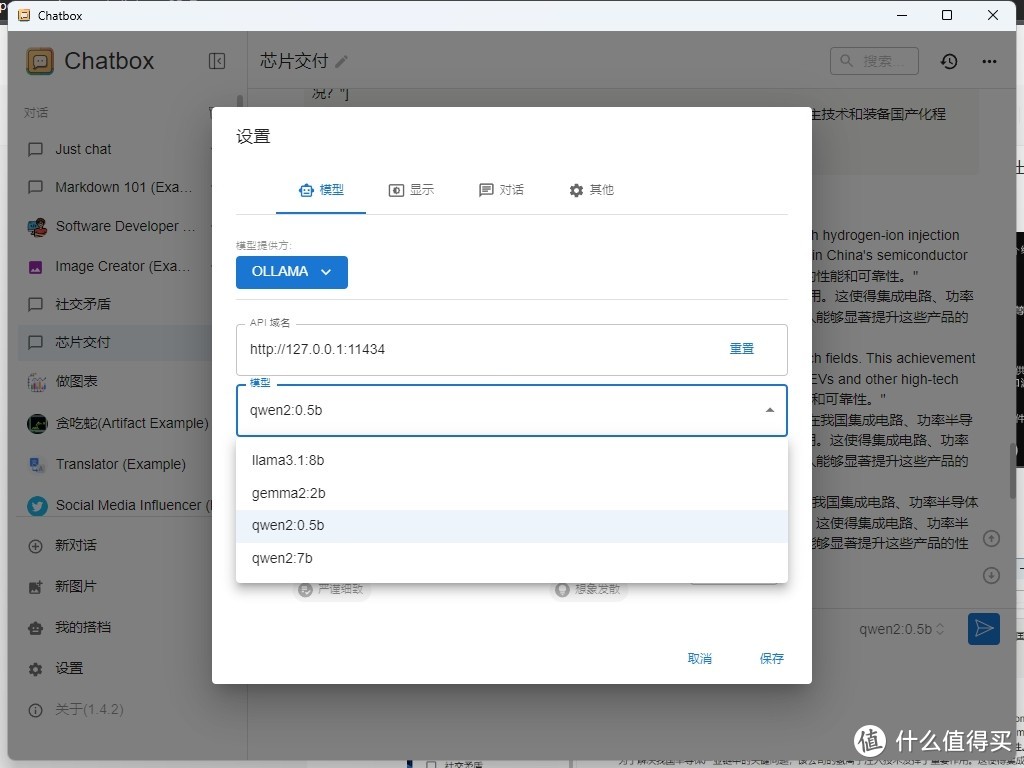
这样两种方法都可以运行了,还没有来得及比较是LM Studio采用的Vulkan框架速度快?还是Ollama采用的ROCm框架?但是我自己比较喜欢Ollama轻量一些所以肉眼看上去速度更快一些,并且下载模型速度快也不需要挂梯子,并且LM Studio下载模型还需要用Hugingface的镜像站hf-mirror.com。
作者声明本文无利益相关,欢迎值友理性交流,和谐讨论~
















我是大明星_
校验提示文案
espeeden
校验提示文案
再多买一点点
校验提示文案
一个人的精彩
校验提示文案
十二烷基硫酸钠
校验提示文案
qika1983
校验提示文案
值友6670047546
校验提示文案
值友6670047546
校验提示文案
再多买一点点
校验提示文案
espeeden
校验提示文案
我是大明星_
校验提示文案
qika1983
校验提示文案
十二烷基硫酸钠
校验提示文案
一个人的精彩
校验提示文案